Comparative Analysis of 3D Super-Resolution Techniques: GANs, Diffusion Models, and CuNeRF
MiRL Lab, IIT Madras
🔗 GitHub: Private Repository | Project Report
Abstract
This project presents a comparative study of advanced 3D super-resolution techniques—Generative Adversarial Networks (GANs), Diffusion Models, and CuNeRF (Neural Radiance Fields)—for enhancing volumetric medical images. High-resolution 3D reconstructions are essential for accurate diagnosis but are often limited by acquisition constraints in CT and MRI. To address this, we focus on z-axis super-resolution, generating high-resolution volumes from low-resolution inputs. Using the IXI T1-weighted Brain MRI dataset, we evaluate the performance of Soup-GAN, DisC-Diff, and CuNeRF models through PSNR and SSIM metrics. The objective is to identify the most effective generative or implicit approach for achieving superior image fidelity and structural detail in 3D medical imaging.
Methodology
SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks
SOUP-GAN enhances MRI resolution by generating high-resolution (HR) thin-slice images from low-resolution (LR) thick-slice inputs. It employs a residual-in-residual dense block (RRDB) architecture combined with a perceptual-tuned GAN to preserve structural details across 3D volumes. The model’s total loss integrates pixel-wise, perceptual, and adversarial components, ensuring both visual fidelity and consistency. Its scale-attention network refines features across multiple resolutions through three stages — pre-attention, multi-scale processing, and post-attention refinement — resulting in sharper and more coherent 3D medical images.
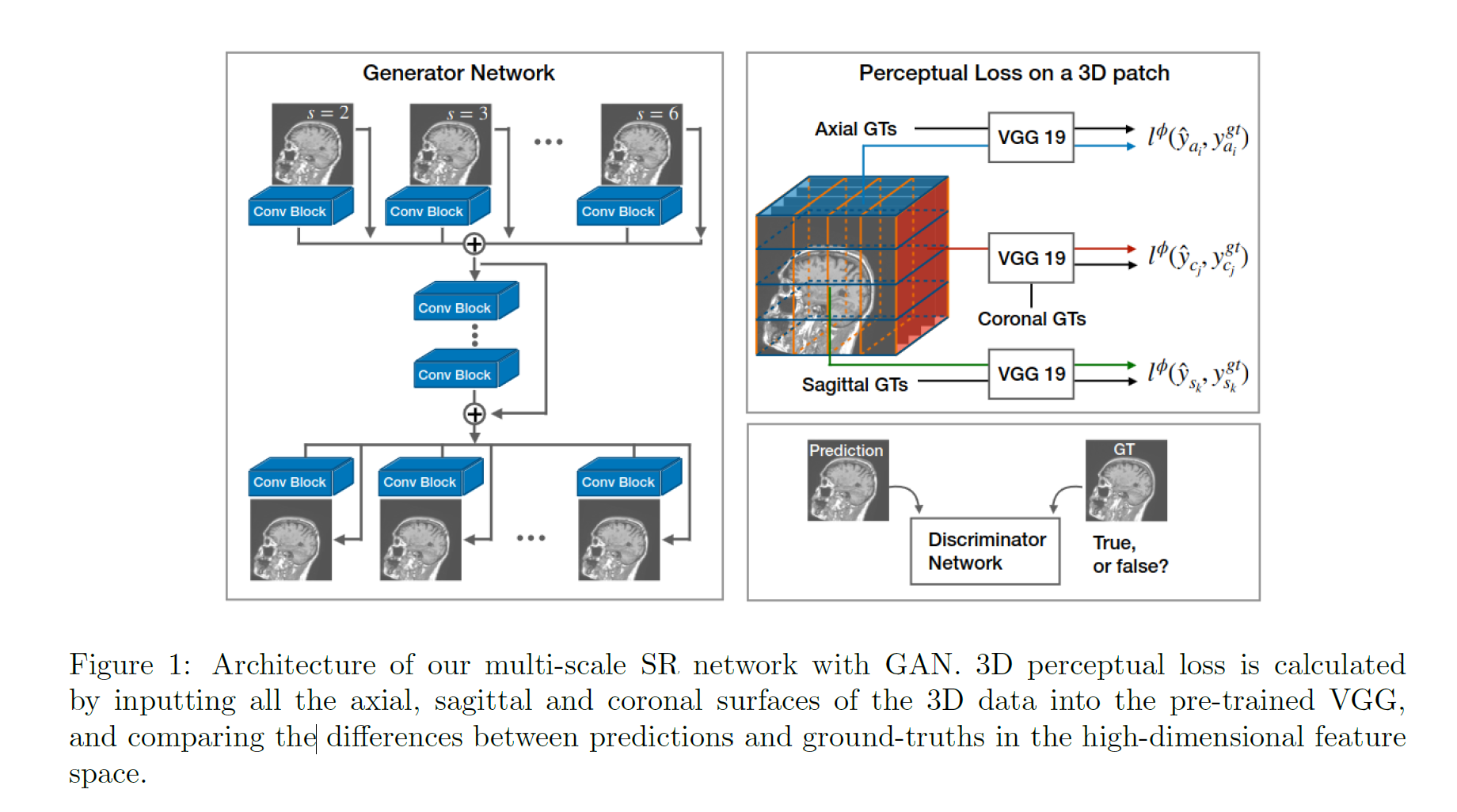
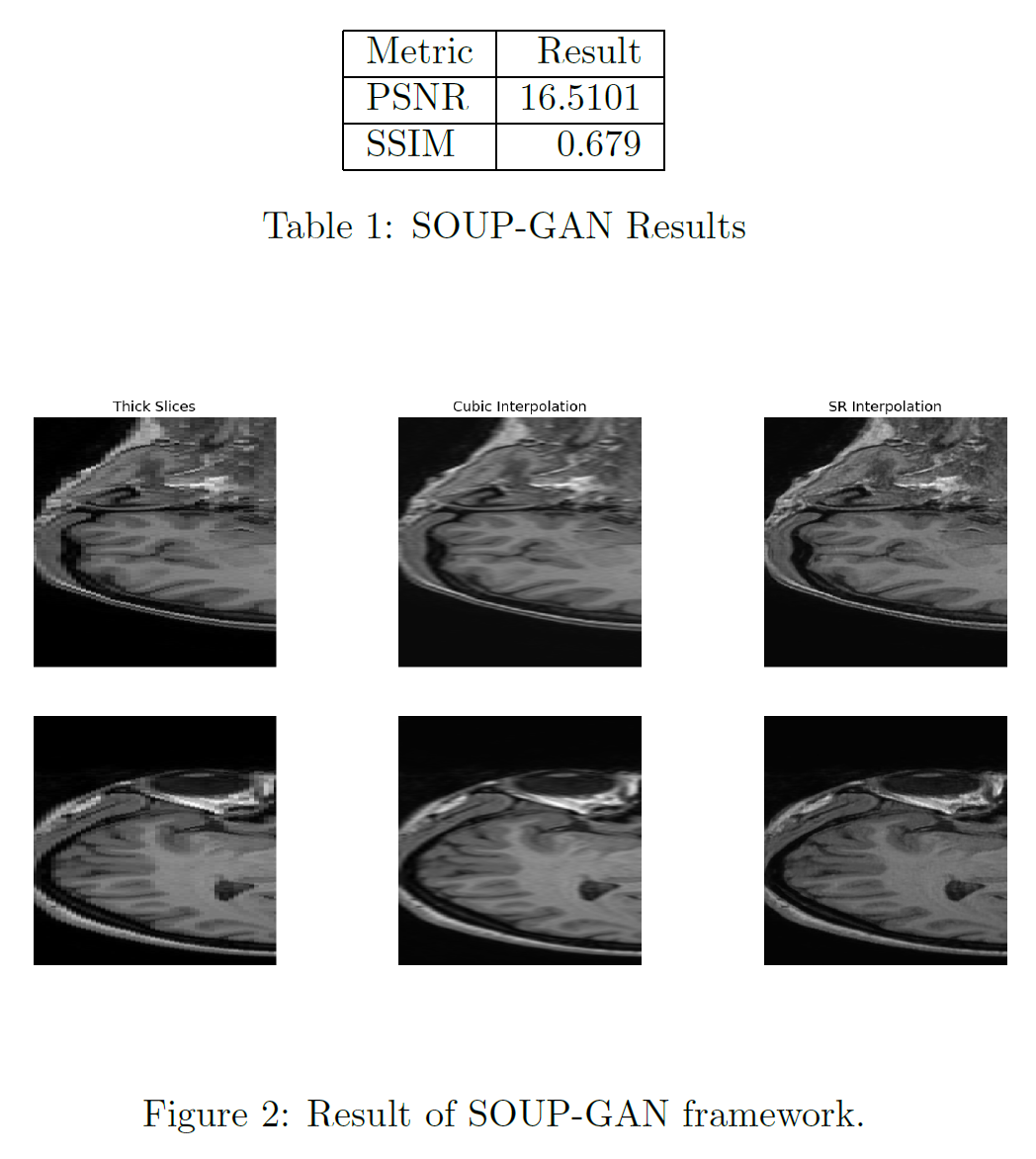
SOUP-GAN achieved a PSNR of 16.51 and SSIM of 0.679 on the IXI T1-weighted Brain MRI dataset, demonstrating moderate reconstruction quality. The model effectively enhanced through-plane resolution along the z-axis, producing visually sharper and more continuous 3D slices compared to cubic interpolation. However, the results also indicate that while structural details were recovered, finer textures and high-frequency features remain partially underrepresented due to limited model capacity and GPU constraints.
DisC-Diff: Disentangled Conditional Diffusion Model for MRI Super-Resolution
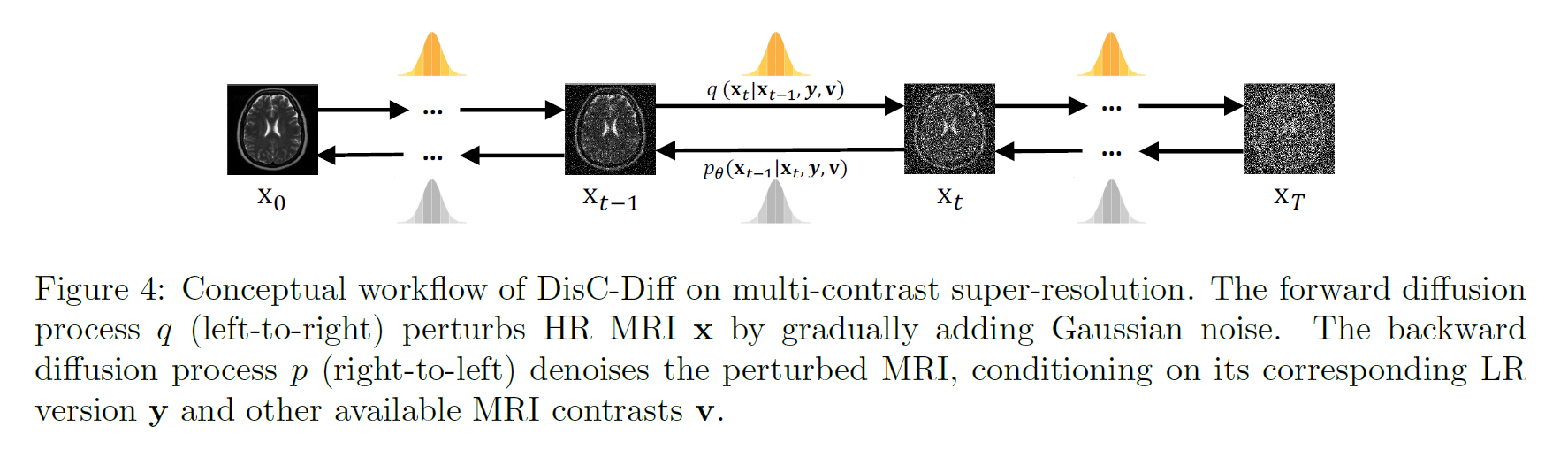
DisC-Diff is a diffusion-based framework designed for multi-contrast MRI super-resolution, enabling effective fusion of complementary information from different MRI sequences (e.g., T1, T2). The model uses a disentangled U-Net architecture that separates shared and independent feature representations before merging them in a decoder to reconstruct high-resolution images.
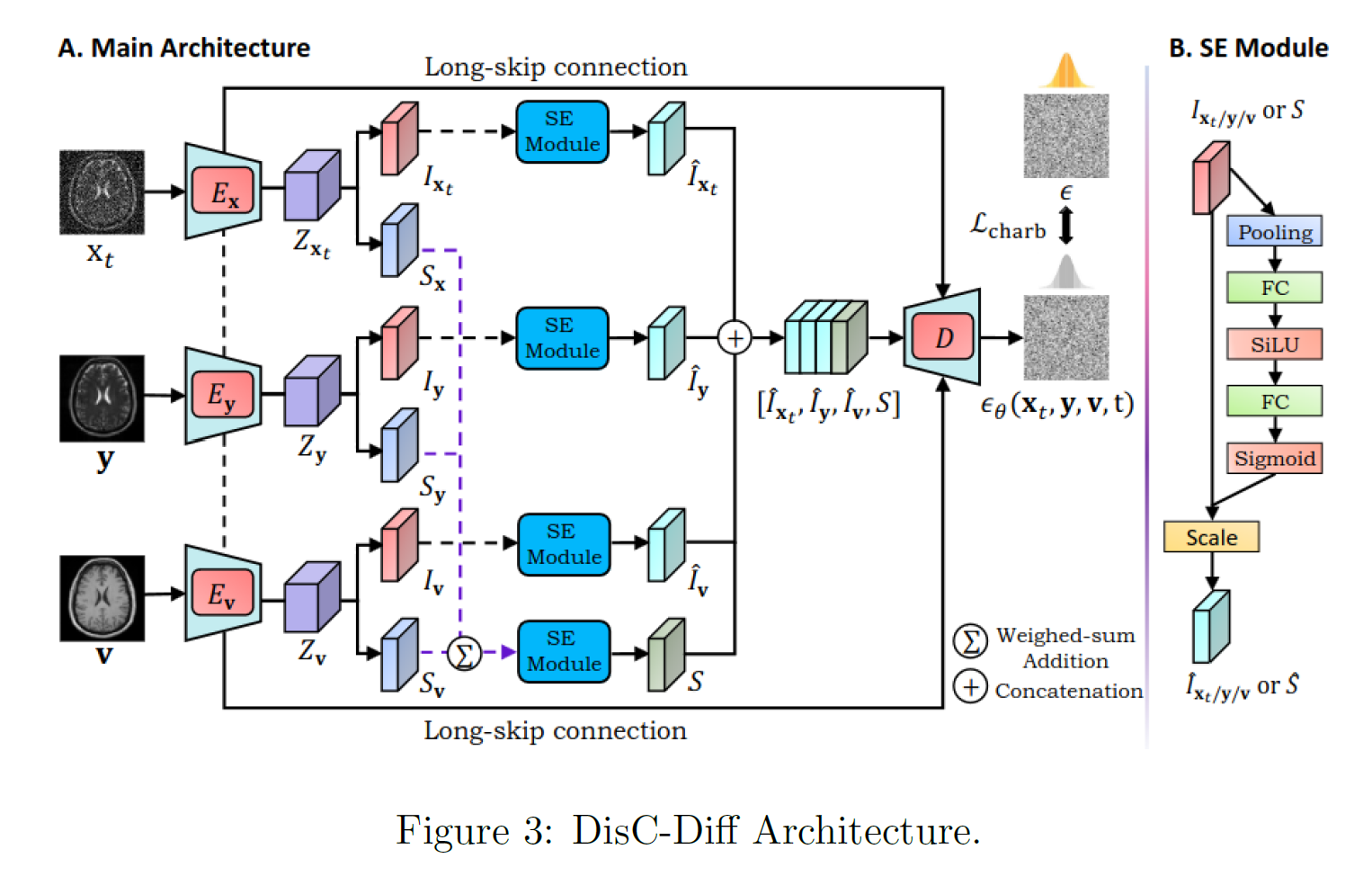
A Squeeze-and-Excitation (SE) module adaptively weights feature importance, while the combined disentanglement and Charbonnier losses ensure smoother convergence and improved edge preservation. The model employs a curriculum learning strategy that progressively trains on simpler to more complex anatomical regions. Through a forward diffusion process, Gaussian noise is added to HR images, and a reverse process reconstructs super-resolved outputs conditioned on multi-contrast inputs.
DisC-Diff achieved a PSNR of 32.14 and SSIM of 0.9612 on the IXI Brain MRI dataset, outperforming both single-contrast and multi-contrast super-resolution methods. The model effectively reconstructed fine anatomical details and maintained high structural fidelity, demonstrating the strong generative capability and stability of diffusion-based frameworks. Among all tested models, DisC-Diff delivered the most consistent and visually realistic 3D outputs, highlighting the potential of diffusion models for high-quality medical image enhancement.
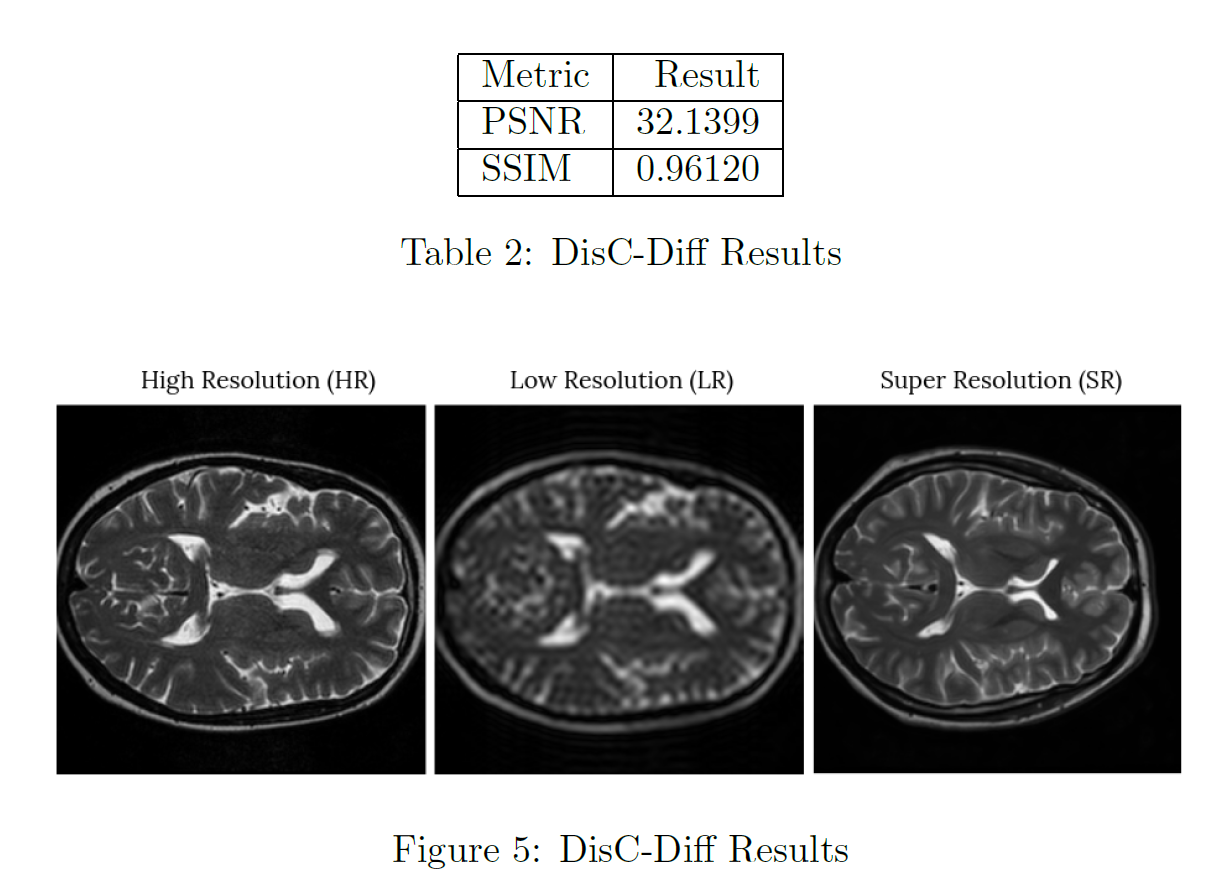
CuNeRF: Cube-Based Neural Radiance Field for Medical Image Super-Resolution
CuNeRF extends Neural Radiance Fields (NeRF) for 3D medical image super-resolution using a cube-based volumetric representation. It integrates cube-based sampling, isotropic volume rendering, and hierarchical cube rendering to reconstruct high-quality medical volumes from low-resolution data.
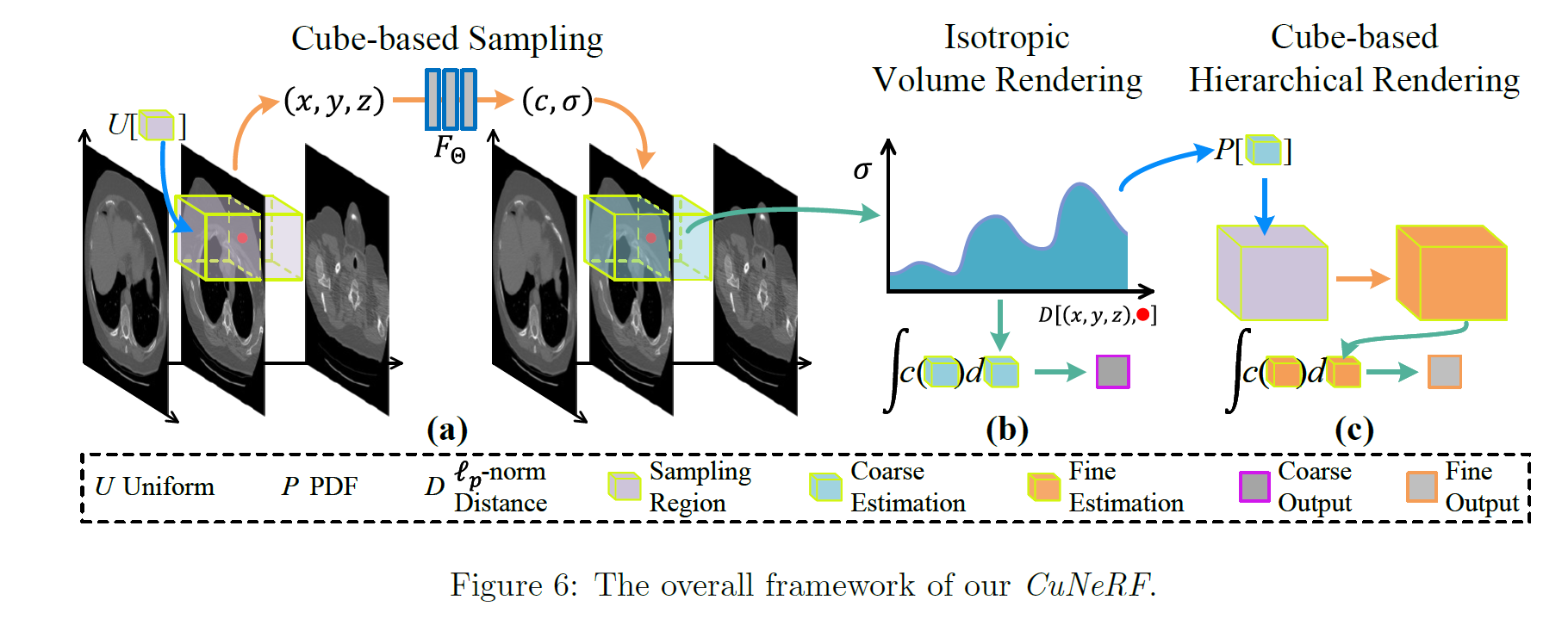
- Cube-Based Sampling: Reduces grid artifacts by sampling multiple points within 3D cubes instead of fixed voxel grids.
- Isotropic Volume Rendering: Integrates light contributions assuming isotropy in the volume density for realistic reconstruction.
- Hierarchical Rendering: Refines predictions by resampling high-density regions, improving resolution and reducing artifacts.
- Slice Synthesis: Enables arbitrary-scale and free-viewpoint slice generation for flexible visualization.
This approach achieves continuous high-fidelity volumetric reconstruction and arbitrary-scale super-resolution with fewer artifacts than traditional methods.
CuNeRF was trained using the Adam optimizer with a weight decay of 1×10⁻⁶ and a batch size of 2048 over 250,000 iterations. The learning rate was gradually reduced from 2×10⁻³ to 2×10⁻⁵. Each 240×240×155 volume required approximately 8 hours for training. During inference, sampling was reduced to 16 points (8 coarse, 8 fine) for efficiency, rendering a full volume in about 20–25 seconds. CuNeRF achieved a peak PSNR of 27.755 and SSIM of 0.818, demonstrating high reconstruction fidelity and structural consistency in medical image super-resolution.
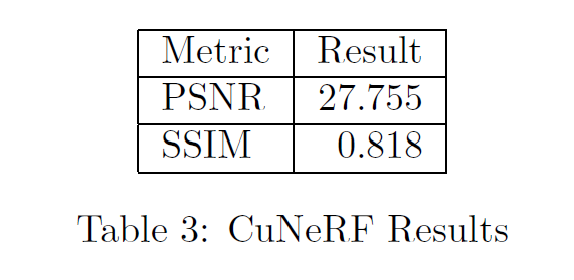
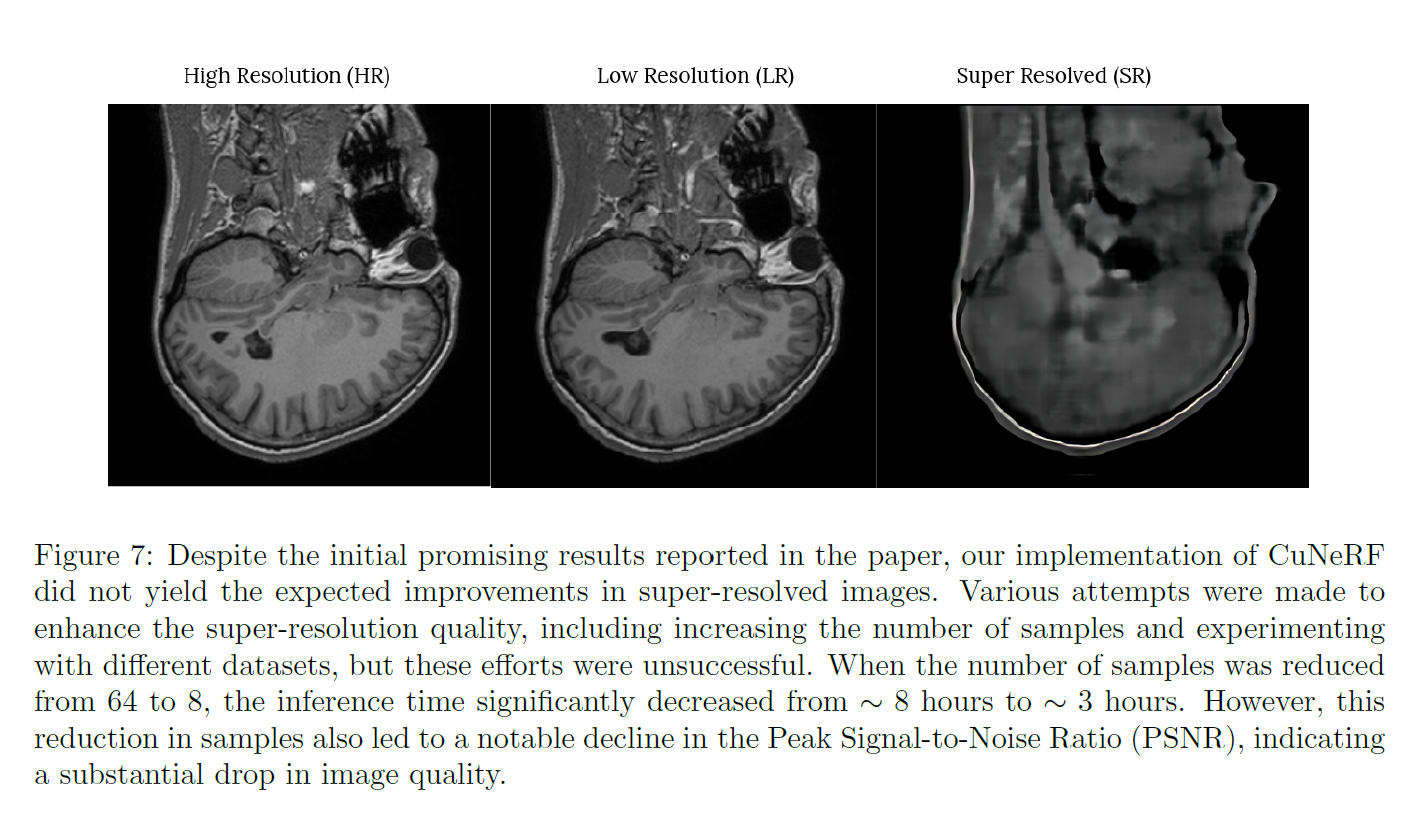
Conclusion & Future Directions
The DisC-Diff model demonstrated the best performance in MRI super-resolution, producing high-quality images with finer anatomical detail compared to SOUP-GAN and CuNeRF. While CuNeRF offered faster inference, it showed a noticeable drop in image quality.
However, some hallucination effects were observed in the DisC-Diff outputs, and its computational cost remains high, making it slower during inference. CuNeRF, though efficient, requires further refinement to match the fidelity required for medical applications.
Future work will explore hybrid architectures that combine diffusion-based detail preservation with the efficiency of implicit models like CuNeRF, along with clinical validation to ensure that improvements translate effectively to real-world medical practice.
</section>