CXRGENIE: A Multimodal Diagnostic Assistant for Chest X-Ray Interpretation and Clinical Reasoning
B.Tech Thesis
🔗 GitHub: Private Repository | Project Report
Abstract
Accurate interpretation of chest X-rays (CXRs) is vital for clinical diagnosis but remains challenging due to complex anatomical structures and subtle pathological cues. Although deep learning has improved automated analysis, existing models typically operate in isolation, limiting multimodal reasoning and explainability. This project introduces an agentic AI workflow that integrates deep learning and large language models (LLMs) for comprehensive and interactive CXR analysis. At its core, the agent leverages GPT-4o-mini as a reasoning agent to coordinate specialized tools for segmentation, classification, grounding, visual question answering (VQA), and report generation. Built using LangChain and LangGraph, the modular framework supports task-based execution. Components include CheXagent for VQA, TorchXRayVision for classification, MedSAM for segmentation, and Maira-2 for grounding. The architecture processes multimodal inputs (text and image) and integrates human-in-the-loop (HITL) feedback to enhance reliability and transparency. A vector database enriched with publicly available and research-authorized radiology knowledge including insights derived from sources such as MIMIC-CXR, Radiology Assistant, and Radiopaedia powers semantic search and retrieval-augmented reasoning. The framework demonstrates strong performance on ChestAgentBench and ChexBench, outperforming open-source medical models like CheXagent and LLaVAMed- 7B in several tasks. Qualitative evaluations show the agent’s ability to reason over complex clinical queries, generate context-aware responses, and reduce hallucinations.
Methodology
Overall System Architecture
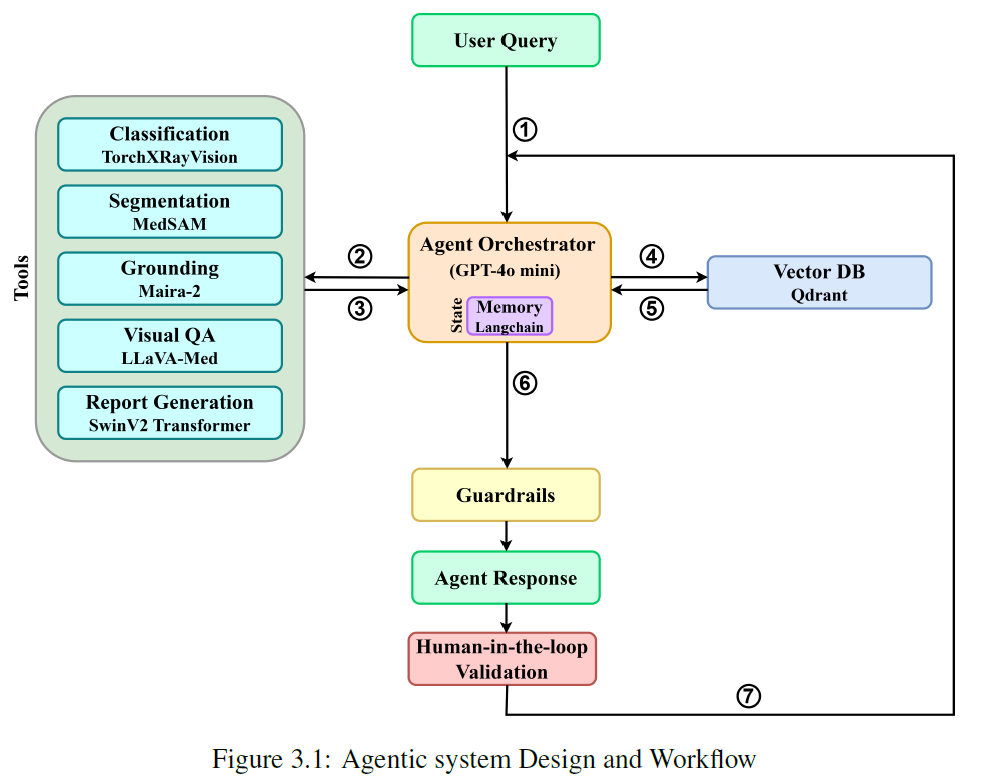
The proposed Multimodal Medical Reasoning Agent for chest X-ray interpretation, is built on a modular and agent-based architecture that integrates specialized tools within a unified reasoning framework. At its core, the system combines deep learning models for segmentation, classification, VQA, visual grounding, and report generation, all coordinated by a central LLM. Unlike passive generative models, the LLM—specifically GPT-4o-mini acts as an intelligent orchestrator. It interprets multimodal inputs, invokes appropriate tools, constructs reasoning chains, synthesizes intermediate outputs, and delivers context-aware diagnostic responses. A key component of this architecture is a vector database enriched with structured medical knowledge, enabling retrieval-augmented reasoning to support grounded and explainable outputs. It also incorporates human-in-the-loop capabilities to enable iterative feedback, expert verification, and transparent decision-making, as well as output guardrails to ensure safe, clinically reliable responses and prevent hallucination. The architecture is implemented using LangChain and LangGraph. LangChain enables seamless integration of external tools, memory modules, and the vector database, while LangGraph provides graph-based control flow with fine-grained state tracking and conditional branching. This design ensures adaptability to varied input scenarios, robust error handling, and safe operation in clinical settings, prioritizing modularity, interpretability.
Core Reasoning Engine
GPT-4o-mini acts as the central orchestrator, coordinating the end-to-end diagnostic workflow for multimodal chest X-ray interpretation. It follows the ReAct (Reasoning + Acting) loop, iteratively reasoning about the problem and invoking tools or actions based on intermediate observations. Upon receiving user input (1) ranging from textbased clinical queries to medical images, the agent, guided by system and role-specific prompts, dynamically selects and invokes appropriate tools (2) for segmentation, classification, grounding, VQA, or report generation.
Tool outputs(3) are parsed and merged into a unified representation. The agent then generates an intermediate response, which is used to query (4) the retrieval-augmented vector database (Qdrant) for relevant external clinical knowledge. This retrieval step (5) enhances the agent’s contextual understanding and enables more informed, grounded reasoning.
Before producing the final output, the agent’s response (6) is passed through guardrails to ensure safety, consistency, and compliance with clinical standards. The final response is then presented for human-in-the-loop validation (7), ensuring that clinicians remain part of the decision-making loop, enhancing reliability, transparency, and trustworthiness in high-stakes diagnostic scenarios.
Workflow Design using LangGraph
Each user session maintains a persistent state that tracks inputs, tool outputs, confidence scores, and final responses enabling adaptive, context-aware, multi-turn interactions.
The reasoning workflow is built as a directed graph using LangGraph, with nodes for tool invocation, result synthesis, and response generation. Conditional branching enables dynamic routing.
After tools produce intermediate outputs, relevant features are encoded and sent to a vector database to retrieve semantically similar cases or explanations. This retrieved context refines the agent’s reasoning and output generation. When ambiguity or low-confidence arises, human-in-the-loop interaction by the clinician helps seeking feedback or verification. The final outputs are synthesized with consistency checks and full traceability to ensure safe and explainable decision-making.
Integrated Tools and Capabilities
The system integrates a suite of specialized tools via standardized APIs to enable robust and clinically meaningful reasoning across key medical imaging tasks. For VQA, it leverages CheXagent to provide image-grounded, contextually relevant answers to complex clinical queries based on chest X-rays. Segmentation is handled by MedSAM, which delivers precise delineation of anatomical structures and abnormalities, supporting both localization and severity scoring. For Spatial Grounding, Maira-2 enables fine-grained localization of abnormalities or anatomical landmarks, enhancing explainability and downstream analysis.
Report Generation is achieved through SwinV2 Transformer model, which produce structured, radiology-style reports using clinically relevant terminology. Disease Classification is powered by DenseNet-121 (via TorchXRayVision), providing probabilistic predictions for common thoracic conditions. Additionally, the system includes utility modules for DICOM metadata parsing, de-identification (removal of personally identifiable information), and visualization of segmentation, bounding boxes, and spatial grounding overlays.
Tool orchestration is managed through modular API calls with standardized input/ output formats. Robust error handling, execution timeouts, and fallback mechanisms ensure dependable tool operation. The outputs from individual tools are passed to a vector database for semantic enrichment and subsequently synthesized by the reasoning agent to generate context-aware responses.
The Text I/O module parses user inputs to extract clinical intent and context, and it structures the outputs for clarity and proper documentation. Guardrails are implemented to ensure that responses remain focused on chest X-ray diagnostics, blocking irrelevant or potentially unsafe queries. The Image I/O module handles image preprocessing and annotates results with masks, bounding boxes, and captions, with synthetic content clearly labelled to prevent misuse.
Semantic Retrieval and Validation via Vector DB
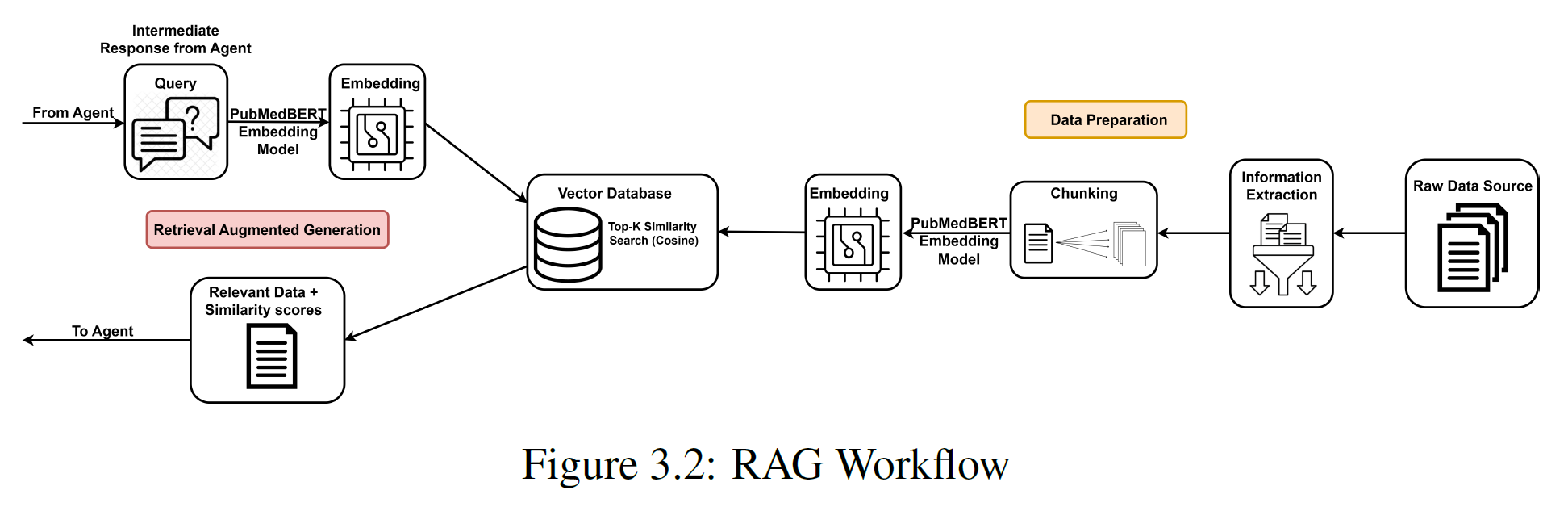
The system integrates a vector database to enhance knowledge retrieval and semantic grounding during diagnostic reasoning. After tool outputs and intermediate results are generated, relevant clinical evidence is encoded into dense vector representations using the PubMedBERT embedding model and queried against a curated research knowledge base informed by publicly available and research-authorized radiology resources—including insights derived from MIMIC-CXR, Radiology Assistant, and Radiopaedia. This retrieval-augmented approach provides semantically rich, context-aware information that grounds the LLM’s responses in verified clinical knowledge, reducing hallucinations and improving diagnostic accuracy.
The vector database also supports similarity searches for user queries and system generated explanations, enabling dynamic access to relevant cases, terminology, and imaging findings. This integration strengthens interpretability, traceability, and clinical safety by continuously validating AI-generated outputs against trusted medical knowledge. During critical reasoning steps, the LLM accesses the vector database through a Retriever API to fetch pertinent information that reinforces or challenges its preliminary conclusions. This retrieval-augmented mechanism enhances the factual grounding of responses and helps mitigate the risk of hallucinated content. Retrieved knowledge snippets are seamlessly integrated into the final output, with appropriate attribution to their original sources, thereby strengthening transparency and clinical reliability.
As shown in Figure 3.2, the RAG workflow begins with the agent’s intermediate response being embedded using PubMedBERT. A top-k similarity search is then performed against the vector database, which contains preprocessed and semantically indexed clinical knowledge. The retrieved evidence is then passed back to the agent to inform its final output, ensuring factual grounding and clinical relevance throughout the reasoning pipeline.
Algorithm for Agentic query processing
The Agentic Query Processing Algorithm enables intelligent, context-aware responses by combining retrieval, reasoning, and generation for medical diagnostics.

Experiments and Evaluation
Experimental Setup
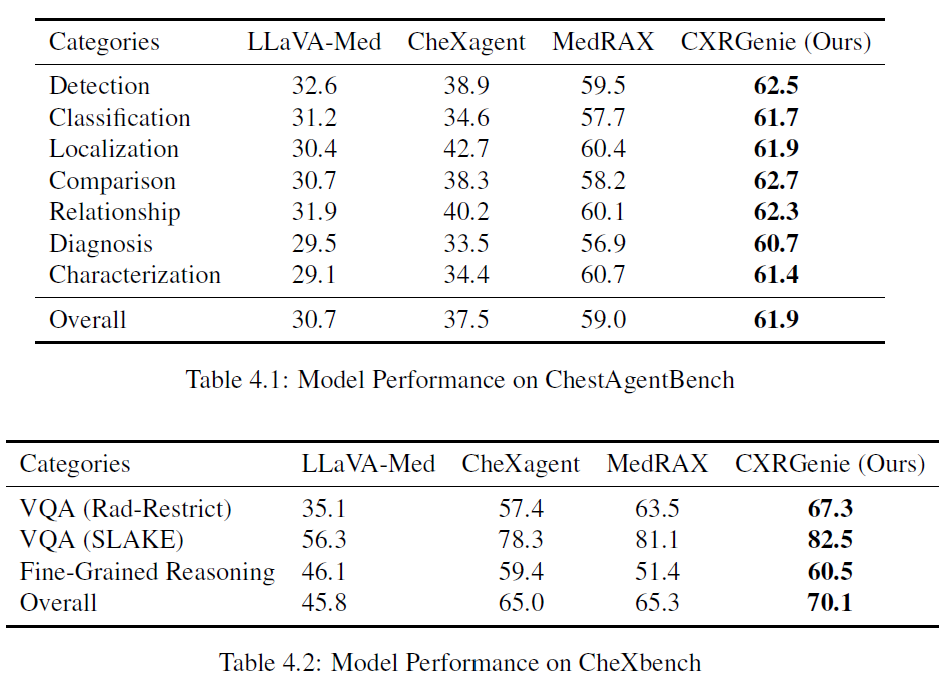
To evaluate the system’s effectiveness in multimodal chest X-ray diagnosis, controlled experiments were conducted using benchmark datasets and clinical diagnostic queries. We used CheXbench and ChestAgentBench publicly available benchmarks designed for evaluating multimodal medical agents: CheXbench includes 238 VQA samples (Rad- Restruct, SLAKE datasets) and 380 fine-grained image-text reasoning (OpenI dataset) questions.ChestAgentBench offers 2,500 questions spanning seven diagnostic categories: Detection, Classification, Localization, Comparison Relationship, Diagnosis, and Characterization. The proposed multimodal agent was evaluated alongside recent vision-language models such as CheXagent, LLaVA-Med-7B and MedRAX, the latter also using GPT-4o-mini as its agent orchestrator.
GPT-4o-mini served as the reasoning engine, prompted with role-based, Chain-of- Thought (CoT), and grounding-enhanced instructions. Integrated tools were orchestrated via LangGraph nodes with deterministic routing and fallback logic based on tool confidence and consistency. A Qdrant-based vector database, using PubMedBERT sentence-transformer embeddings and structured knowledge base, enabled semantic retrieval to support evidence grounding and verification.
Safety mechanisms included PII scrubbing, confidence score tracking, and Humanin- the-Loop overrides for ambiguous or low-confidence cases. For automated evaluation, HITL was disabled to ensure uninterrupted comparison and fair benchmarking.
All experiments were run on an NVIDIA RTX A6000 GPU (48GB VRAM) with 256GB system RAM, supporting real-time inference, tool orchestration, and scalable multimodal processing.
Quantitative Results
The agent was evaluated on VQA tasks using the ChestAgentBench and ChestBench datasets. It achieved competitive accuracy compared to state-of-the-art VLMs, demonstrating its capacity to understand and respond to complex clinical queries based on chest X-ray images. These results (Table 4.1, Table 4.2) show the effectiveness of the multimodal reasoning architecture in medical VQA.
Qualitative Results
To demonstrate the reasoning capabilities and interpretability of the reasoning agent, two representative diagnostic scenarios involving chest X-ray images are presented. Each example includes a complex user prompt that mimics real-world clinical queries, followed by the system’s end-to-end response. The outputs showcase integrated tool usage (e.g., segmentation, grounding, classification), retrieved knowledge references, and the final reasoning chain produced by the language model. These qualitative cases highlight the agent’s ability to generate evidence-backed answers, localize abnormalities, and structure responses in clinically relevant formats—reinforcing both accuracy and transparency in decision-making.


Ablation Study Results
To evaluate the contribution of individual components to the overall diagnostic performance of the proposed agent, an ablation study was conducted on the CheXbench dataset. As shown in Figure 4.3, key components namely the vector database, LangChain memory, and external tools were systematically removed from the full agent pipeline, and the performance was also tested using only the LLM module. The resulting impact on diagnostic accuracy was measured.
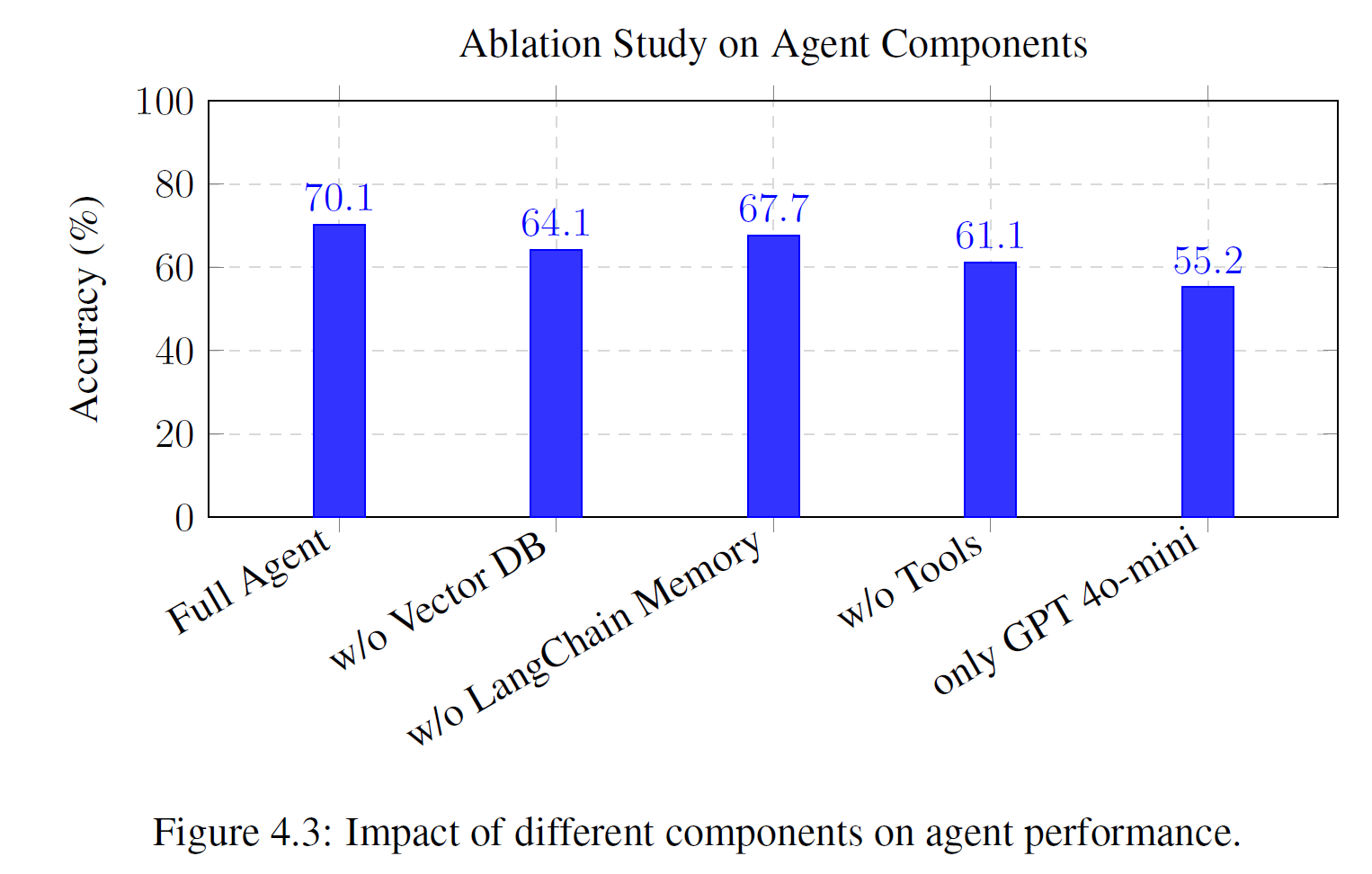
The full agent, which integrates the LLM (GPT-4o-mini), vector database, LangChain memory, and external tools, achieves the highest accuracy of 70.1%. Removing the vector database reduces accuracy to 64.1%, indicating its critical role in enabling retrievalaugmented reasoning. Excluding LangChain memory leads to a smaller drop to 67.7%, suggesting its usefulness in preserving conversational and task-related context. Notably, removing external tools results in a more substantial decrease to 61.1%, emphasizing their importance in extending the agent’s capabilities beyond pure language understanding. Finally, using only the GPT-4o-mini model, without any supporting components, results in the lowest accuracy of 55.2%, emphasizing the importance of the full system’s architecture for effective multimodal and context-aware reasoning.
Overall, the ablation study demonstrates that each module contributes meaningfully to the agent’s performance, and their synergistic integration is essential for achieving optimal diagnostic accuracy.
System Performance
On average, the agent produced answers in 104 seconds on the ChestAgentBench dataset and 108 seconds on the CheXbench dataset. Across all experiments, inference times ranged from 12 seconds for simple look-ups to 198 seconds for the most tool-intensive queries. This latency is acceptable for clinical use, balancing responsiveness with the computational demands of multimodal reasoning and thus enabling near-real-time integration into diagnostic workflows. These measurements affirm the system’s capability to handle multimodal tasks efficiently.
Conclusion
This work presents CXRGENIE - a multimodal agentic workflow for intelligent chest X-ray interpretation that unifies disease classification, segmentation, visual grounding, VQA, and report generation. By integrating deep learning and large language models through LangChain and LangGraph, the system performs coordinated reasoning across multiple specialized tools, delivering reliable and explainable diagnostic support.
Leveraging GPT-4o-mini as the central reasoning agent, the system achieved competitive results on benchmark datasets such as ChestAgentBench and CheXbench, outperforming leading open-source medical models in complex multimodal reasoning tasks. Its integration of retrieval-augmented reasoning and human-in-the-loop validation enhances factual grounding, interpretability, and clinical reliability.
Overall, CXRGENIE demonstrates how agentic workflows can bridge the gap between explainable AI and real-world clinical decision support, setting the stage for trustworthy, multimodal reasoning systems in healthcare.
Future Works
Future work will focus on expanding CXRGENIE beyond chest radiographs to support modalities such as CT, MRI, and Ultrasound, as well as integrating patient history and laboratory data for richer contextual reasoning. Reinforcement learning with clinician feedback (RLHF) will be explored to continually refine decision quality and adapt behavior in real time.
Integration of medical ontologies (e.g., SNOMED-CT, UMLS, RadLex) and Graph Neural Networks will enable concept-driven diagnostic reasoning and improve semantic consistency. Enhanced retrieval with graph-based RAG and cross-encoder reranking will further boost factual precision.
Finally, a decentralized multi-agent architecture using the Multi-Agent Communication Protocol (MCP) will be investigated to assign specialized reasoning and retrieval tasks to cooperating agents — paving the way toward scalable, distributed clinical AI systems.
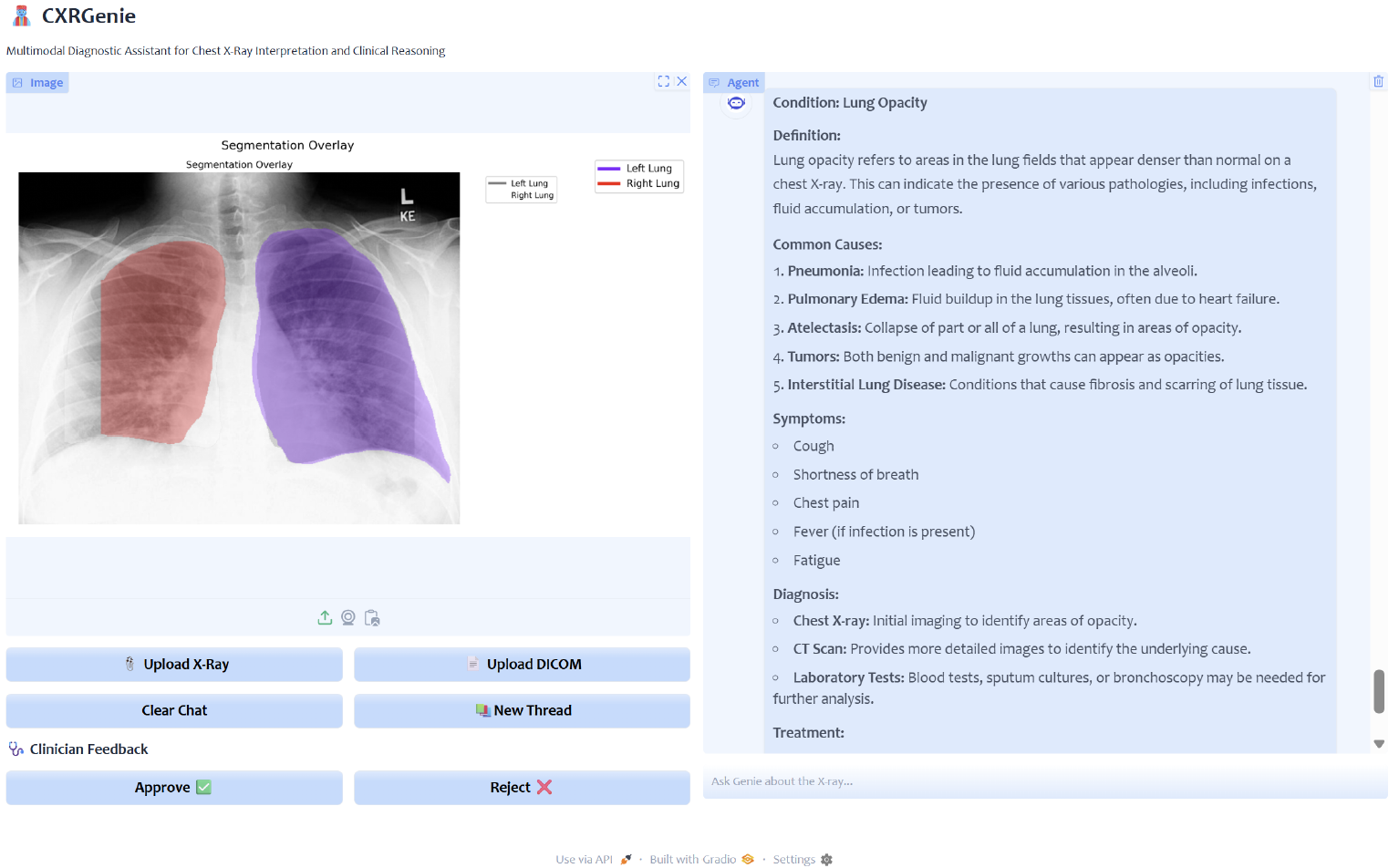
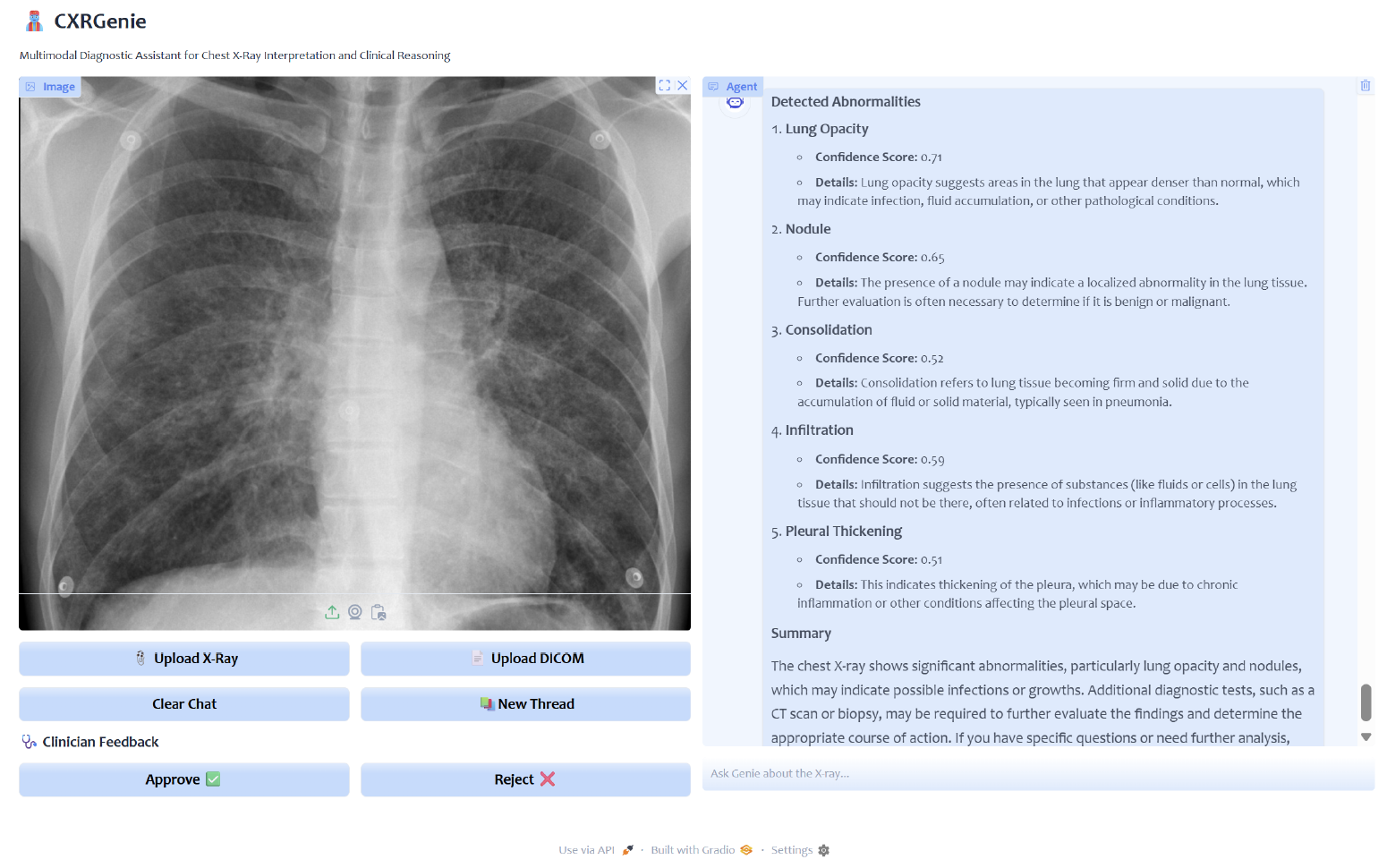
Interface Design
All the UI interfaces were developed using Gradio, a Python library used for creating interactive, web-based user interfaces for machine learning models, APIs, and Python functions. Gradio simplifies building and sharing demos or applications.