FusionDecompNet: A Multimodal Multitask Learning Framework for Alzheimer’s Diagnosis via Joint MRI-PET Fusion and Auxiliary Modality Reconstruction
| Dr. Ram Thaila Scholarship Project | Guide: Varun P. Gopi | MICAIH Lab, NIT Trichy |
🔗 GitHub: Private Repository | Project Report
Abstract
Alzheimer’s disease (AD), a progressive neurodegenerative disorder and the leading cause of dementia, affecting over 33 million people globally. With the aging population increasing—especially in low- and middle-income countries—the number of AD cases is expected to reach 152 million by 2050. Characterized by betaamyloid plaques, tau tangles, and progressive brain atrophy, AD leads to memory loss and cognitive decline. Early and accurate diagnosis is crucial for timely intervention yet remains a significant challenge. Multimodal neuroimaging, particularly Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET), provides complementary information about the brain’s structure and function. However, effectively integrating these modalities remains a complex task. To address this, a unified multitask deep learning framework (FusionDecompNet) is proposed that combines multimodal image fusion, auxiliary decomposition, and cognitive status classification to enhance AD diagnosis. MRI and PET images are processed through parallel encoders using multi-scale convolutions and attention mechanisms to extract rich, modality-specific features. These are fused via a triple attention mechanism to generate a unified representation capturing both structural and functional information. The decomposer module reconstructs the input modalities, providing a self-supervised signal that helps the model learn distinct and informative features. The fused image is then used by a classification module to predict cognitive status for multiclass diagnosis, distinguishing among Normal Control (NC), Mild Cognitive Impairment (MCI), and Alzheimer’s Disease (AD) classes. Experimental evaluations demonstrate superior performance compared to unimodal and single-task baselines. This work presents a robust, interpretable, and end-to-end deep learning solution for Alzheimer’s Disease diagnosis, offering significant potential for clinical translation and early-stage cognitive assessment.
Methodology
The proposed system for Alzheimer’s Disease (AD) diagnosis is built on a multimodal, multitask deep learning framework designed to integrate both structural and functional brain information from T1-weighted MRI and FDG-PET scans. The objective is to improve the diagnostic accuracy and interpretability of AD progression by leveraging the complementary nature of these imaging modalities.
The model jointly learns three interrelated tasks: (1) multimodal image fusion, (2) auxiliary decomposition of the fused representation into modality-specific components, and (3) disease classification. This multitask setup enables the network to simultaneously optimize for both representational quality and clinical classification performance.
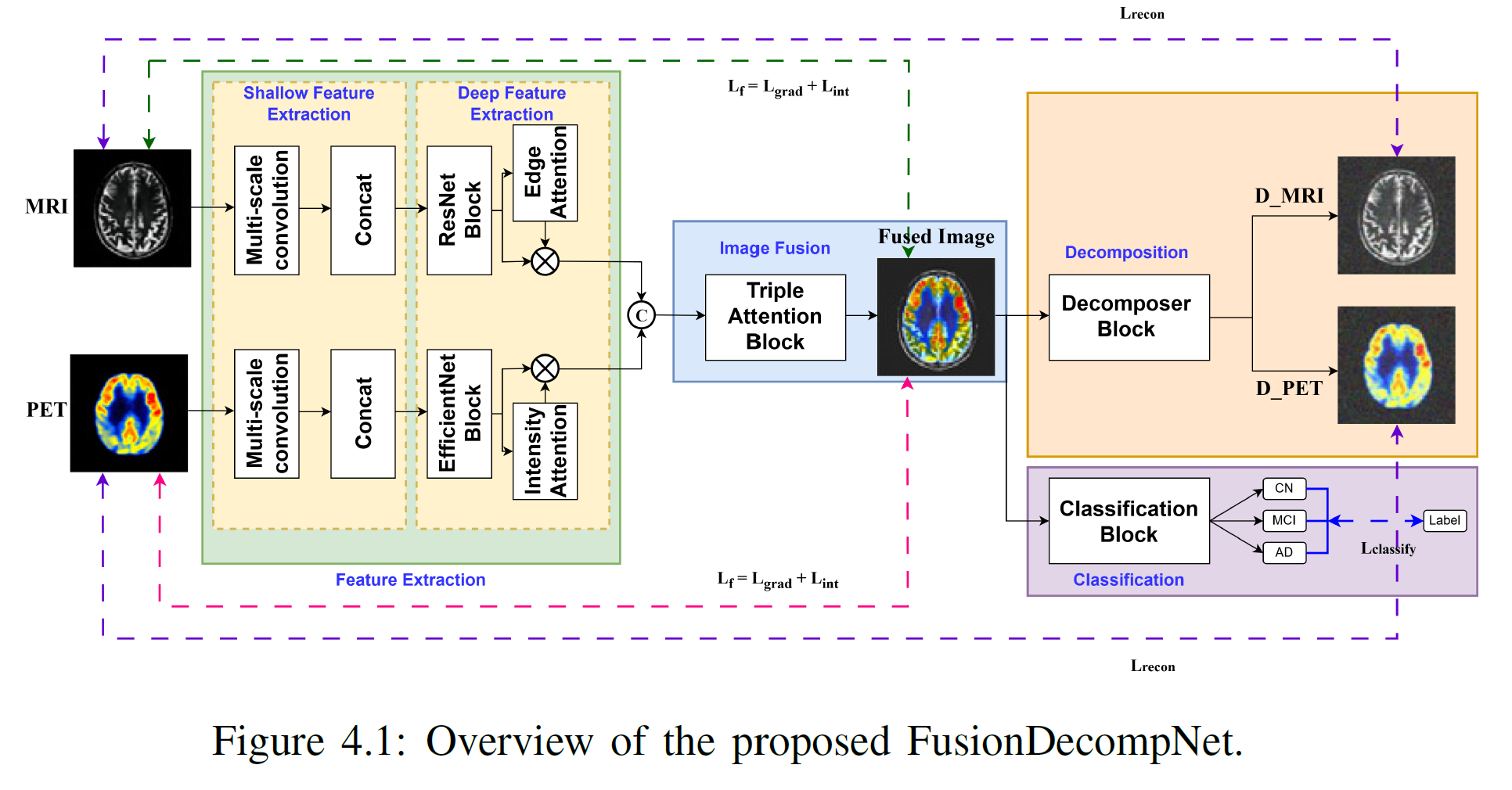
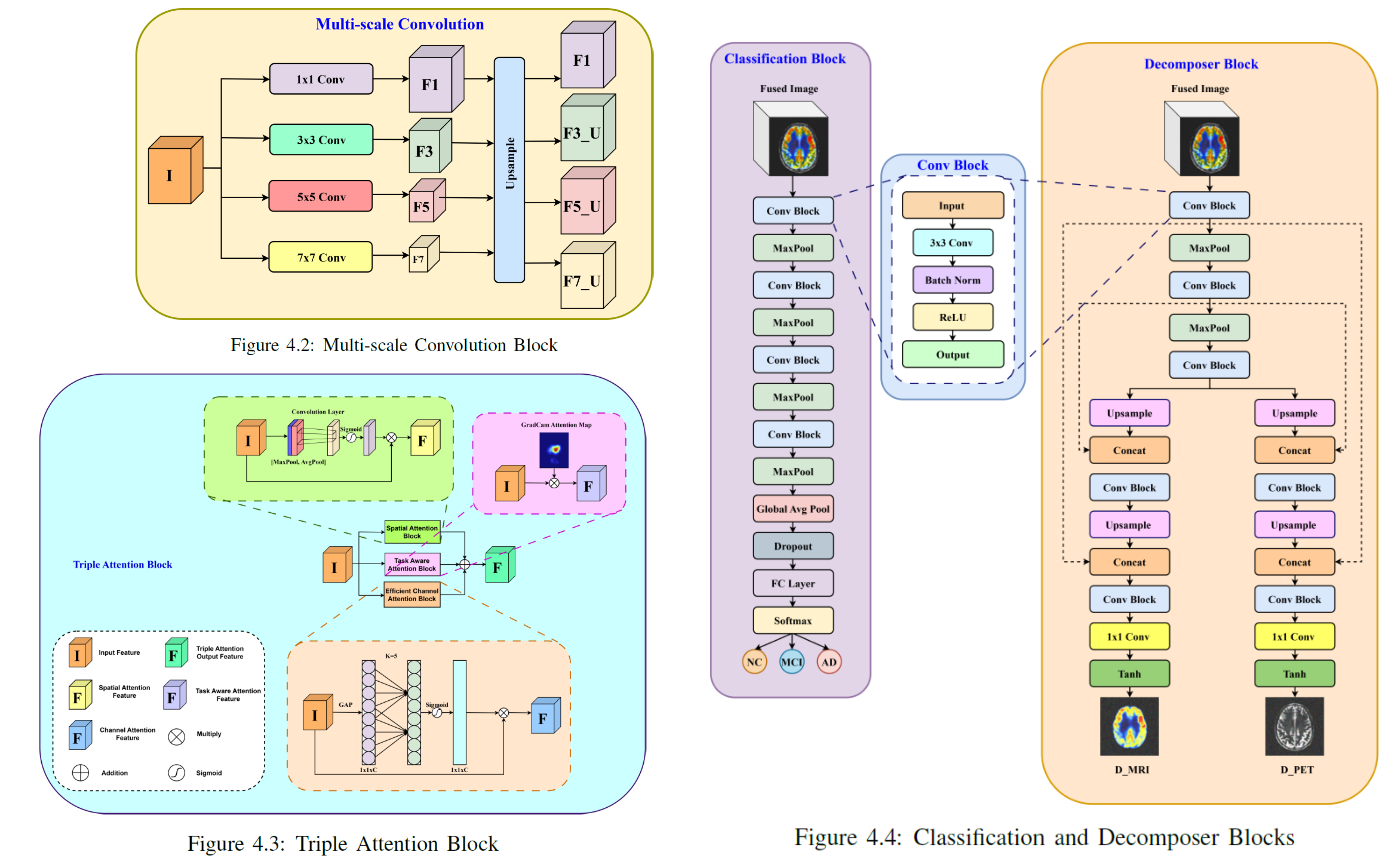
The architecture begins with parallel feature extraction pathways for MRI and PET images. Each pathway employs multi-scale convolutional encoders enhanced with attention mechanisms to capture both shallow structural cues and deep semantic representations unique to each modality. The extracted features are adaptively merged using a Triple Attention Fusion Module, which selectively emphasizes modality-specific regions and contextual dependencies.
To ensure the fused image retains meaningful information from both modalities, a Decomposer Module reconstructs the original MRI and PET images from the fused representation. This auxiliary self-supervised learning objective, guided by reconstruction loss, enforces the preservation of critical modality-relevant information and prevents overfitting to classification signals alone.
The Classification Module receives the fused representation and outputs the cognitive state of the subject — categorized as Normal Control (NC), Mild Cognitive Impairment (MCI), or Alzheimer’s Disease (AD). The decomposition and classification branches are trained jointly, ensuring that the network learns disentangled yet complementary features. This multitask design improves robustness, interpretability, and diagnostic precision, effectively bridging multimodal fusion and clinical decision-making in AD analysis.
Overall, this unified multitask learning framework integrates fusion, decomposition, and classification in a single architecture, enabling efficient joint optimization and improved generalization. The auxiliary decomposition task further acts as a regularizer, guiding the fusion process toward more interpretable and physiologically meaningful representations—a crucial step toward explainable and data-efficient neuroimaging analysis.
Implementation
The model was developed on a high-performance Ubuntu 20.04 system (Intel i9-12900K, 128 GB RAM, NVIDIA RTX A6000 48 GB VRAM) using Python 3.9 / PyTorch 2.0.1. Key libraries included MONAI and SimpleITK for medical imaging, nibabel for NIfTI handling, and Albumentations for augmentations. CUDA 11.8 with cuDNN enabled efficient GPU acceleration.
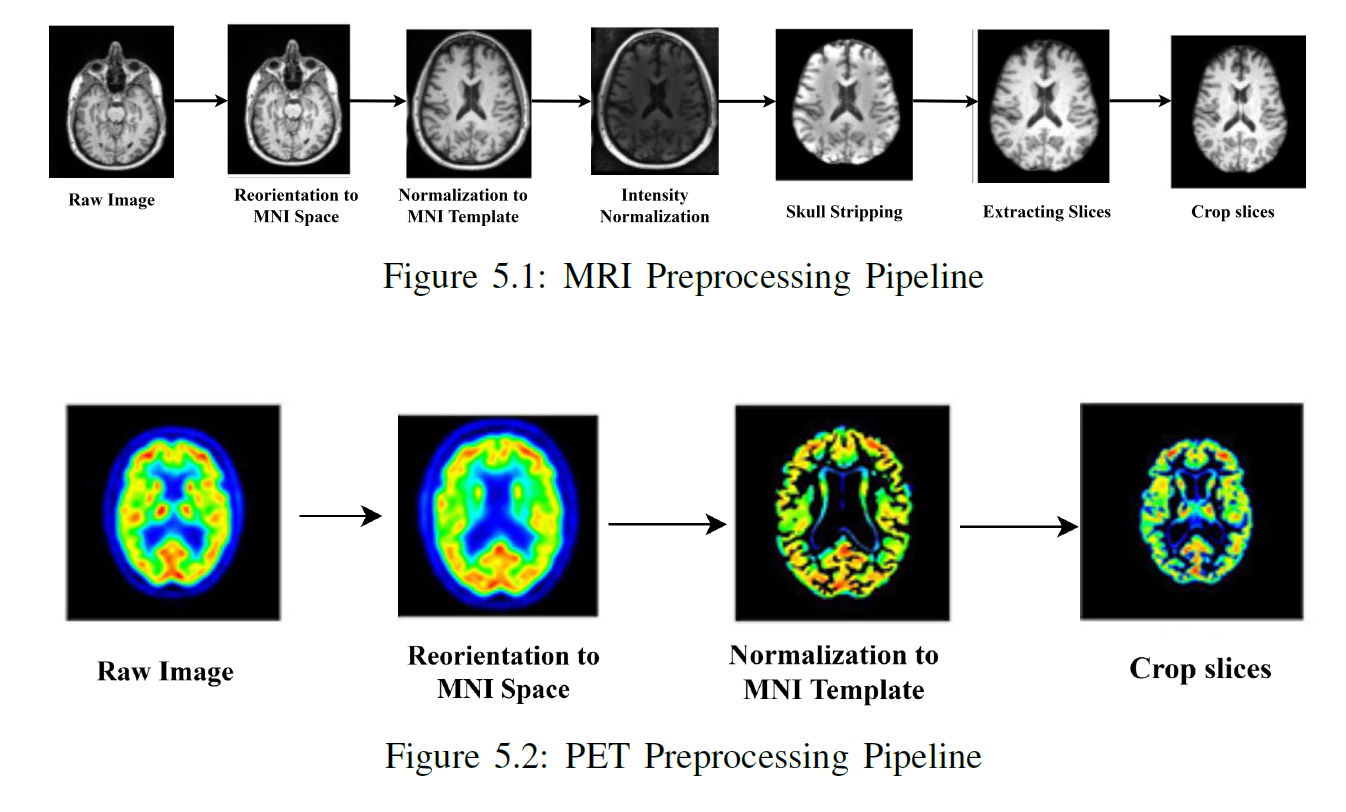
The preprocessing pipeline ensured consistent, high-quality multimodal inputs. FDG-PET scans were rigidly registered to MRI using mutual-information alignment, resampled to 1×1×1 mm spacing, and standardized to 128³ voxels. MRI intensities were Z-score normalized, while PET values used min-max scaling (0–1 range). Data augmentation introduced random rotations, elastic deformations, Gaussian noise, and intensity shifts to enhance robustness. The normalized MRI and PET volumes were stacked channel-wise as multimodal inputs, with labels one-hot encoded for binary and multiclass AD classification.
Experimental Results
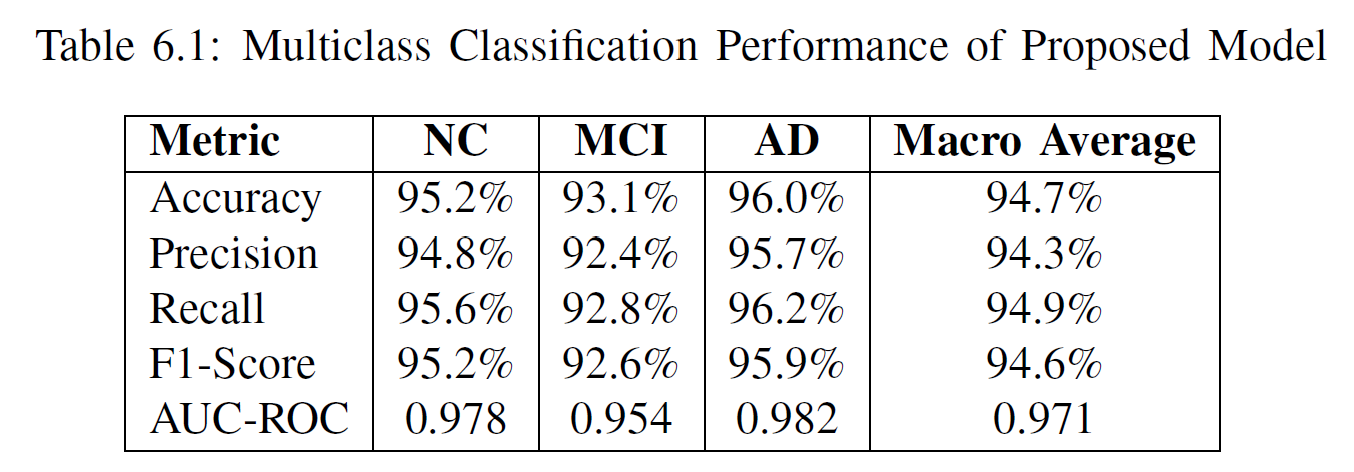
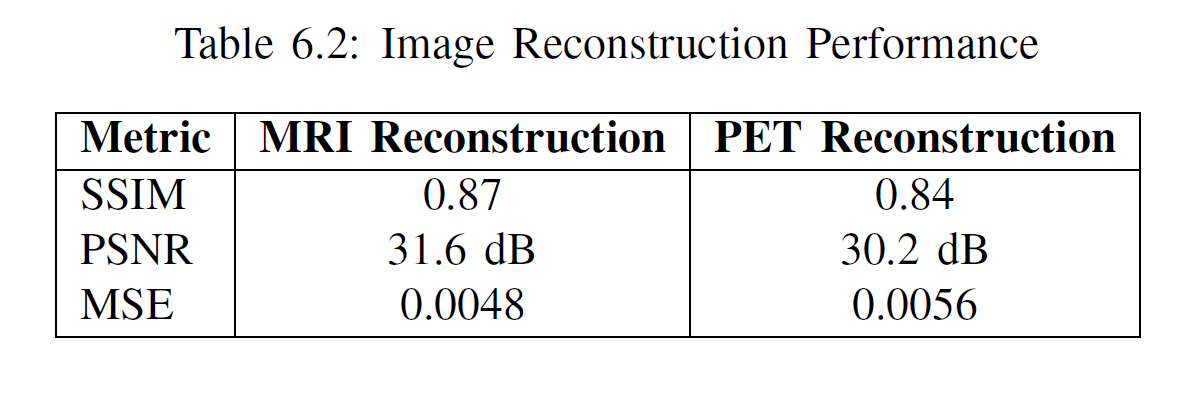
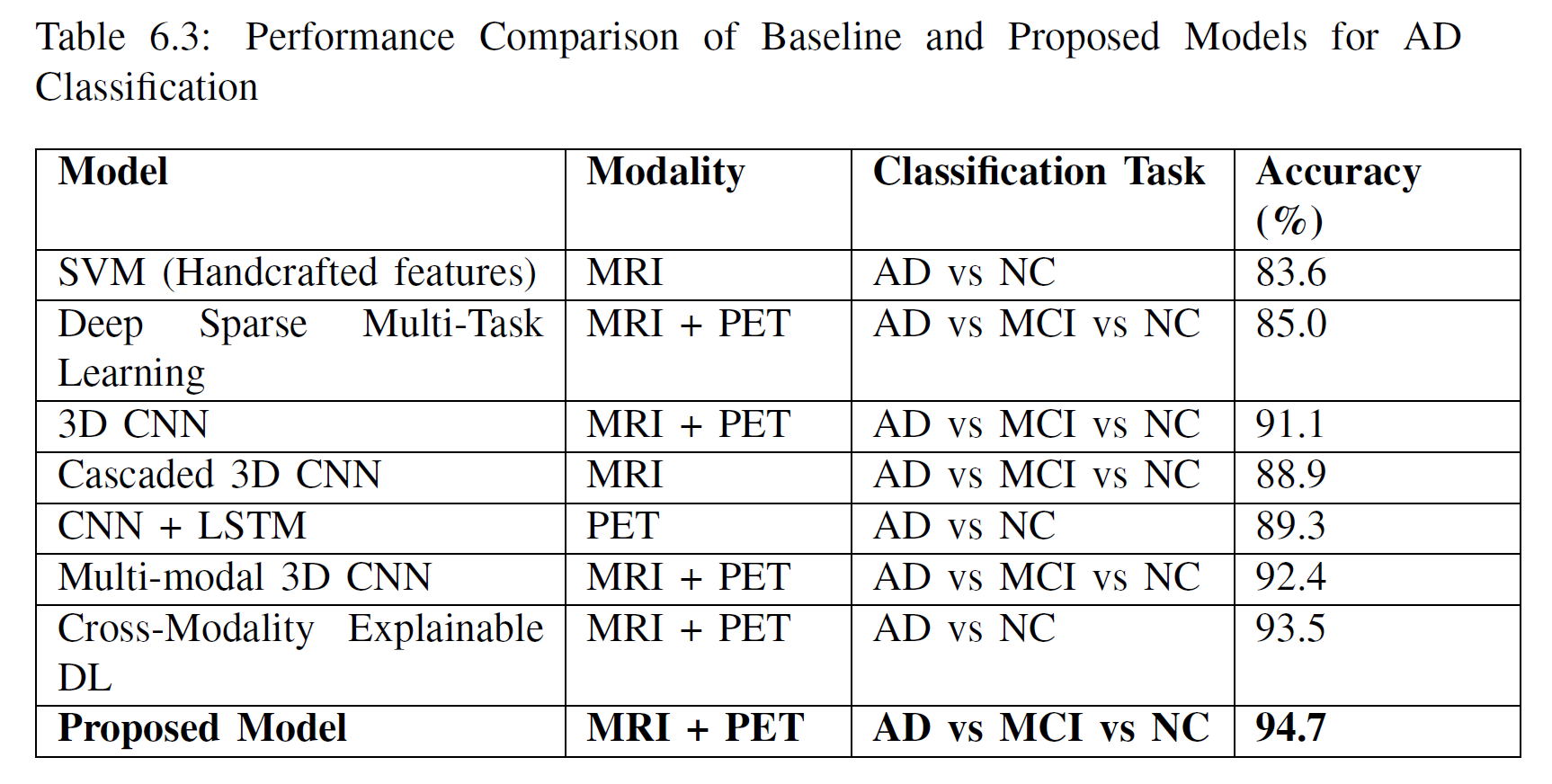
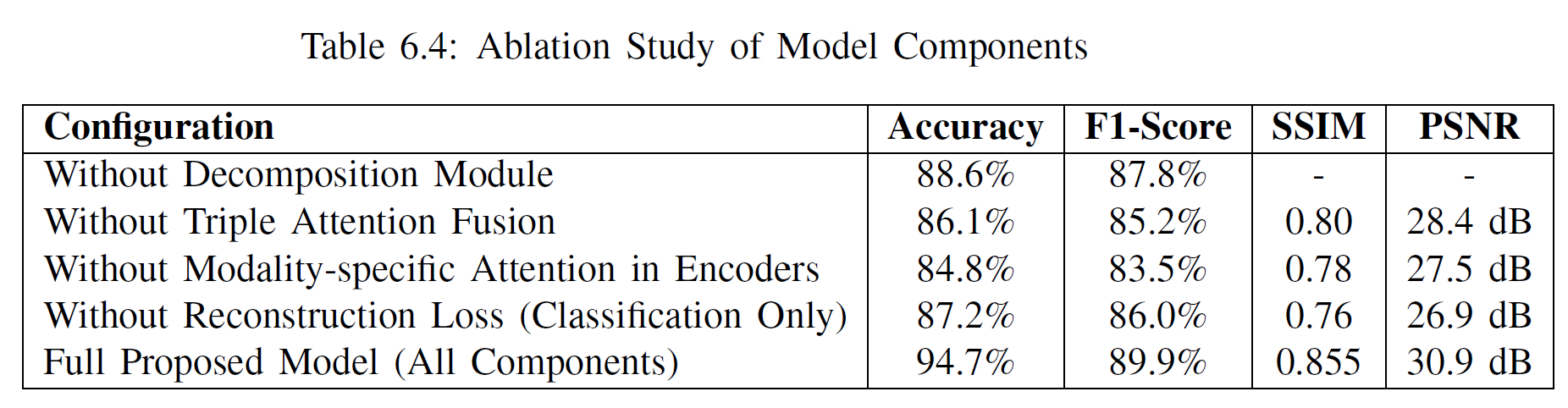
The proposed multi-modal fusion model demonstrated strong performance across the three-class classification task (NC vs. MCI vs. AD), achieving a 94.7% accuracy and outperforming multiple baseline CNN and transformer-based fusion methods. The decomposition module enabled high-fidelity MRI and PET reconstruction (SSIM ≈ 0.87–0.84; PSNR ≈ 31–30 dB), indicating effective retention of modality-specific features. Ablation studies confirmed that the decomposition module, attention-based fusion, and modality-specific encoders each significantly contribute to the final performance, highlighting the model’s effectiveness in learning complementary structural and functional brain information.